Monitoração - Produção¶
Visão Geral¶
A monitoração de um ambiente produtivo tem como principal objetivo detectar ofensores dos sistemas antes que ocorra uma falha ou degradação geral do sistema que está sendo monitorado, identificando possíveis problemas que possa afetar a operação, otimizar recursos através da análise das métricas coletadas e receber alertas para notificar equipes sobre eventos críticos ou tendências anormais.
A interface deve ser simplificada indicando somente os recursos que estão com alerta amarelo ou vermelho. Alerta amarelo é um indicador que há grande chance de haver impacto. Por exemplo, um disco que está com ocupação de acima de 80% de sua capacidade.
Alerta vermelho é um indicador que há impacto em um dos componentes do cluster. Por exemplo, um dos nós do cluster do openshift está indisponível mas os outros nós estão suprindo sua falta.
Os recursos que estão funcionando corretamente, dentro da normalidade, não devem aparecer no dashboard de alerta porque a informação relevante é aquela que há problemas nos pontos monitorados.
O ambiente de monitoração Zabbix deve estar em servidores exclusivos e independentes da solução a ser monitoração. Por exemplo, o Zabbix necessita de um banco de dados MySQL que deve não deve ser compartilhado com mais nenhuma outra solução. A exclusividade e independência dos recursos é necessário em virtude da confiabilidade que o sistema de monitoramento de ter. Um sistema de monitoração instável gerará muitos falsos positivos, desacreditando totalmente a solução.
Finalmente, o sistema de monitoração deve ter integração com um sistema de chamados, para gerenciamento de problemas, registro de problemas e respectivas ações corretivas, bem como ter a possibilidade geração de relatórios e performance dos SLAs.
Caso exista a necessidade de uma apresentação para o cliente segue o link da apresentação Monitoramento_Zabbix.pptx
Sobre a ferramenta de Monitoração Zabbix¶
1. Características¶
-
O Zabbix é projetado para ser dimensionado desde pequenos ambientes, com poucos dispositivos, até grandes ambientes com milhares de dispositivos monitorados
-
Monitoramento distribuído – Através dos seus Proxies, é possível a coleta das informações de forma descentralizada e reunir as informações centralizando-as através do Zabbix Server
-
Alto Desempenho – Ele é projetado para extrair as informações necessárias e armazená-las de forma ágil em seu sistema de banco de dados
-
Agente Zabbix – Ele é utilizado com padrão para coleta efetiva do maior número de informações do host
-
Fácil Integração com outros sistemas
2. Elementos da arquitetura do Zabbix¶
- Interface web
Uma interface web é fornecida para permitir fácil acesso ao Zabbix de qualquer local ou plataforma. A interface faz parte do servidor Zabbix e geralmente roda na mesma máquina física do servidor.
- Proxy Zabbix
O proxy atua como proxy e pode coletar dados de desempenho e disponibilidade em nome do servidor Zabbix. Esta é uma parte opcional de uma implantação Zabbix, mas pode ser muito benéfica para distribuir a carga de um único servidor Zabbix.
- Agente Zabbix
Um agente Zabbix é um programa especial que permite a comunicação com o servidor mestre. Ele monitora ativamente os recursos e aplicações locais e reporta os dados coletados ao servidor Zabbix.
O Zabbix pode monitorar milhares de dados de servidores, máquinas virtuais, aplicações e dispositivos de rede em tempo real. Isso permite detectar problemas antes que eles chamem a atenção dos usuários.
3. Sizing¶
| Nome | Plataforma | CPU/Memória | SGDB | Host monitorados |
|---|---|---|---|---|
| Small | CentOS | Virtual Appliance | MySql ou InnoDB | 100 |
| Medium | CentOS | 2 cores/ 2G | MySql ou InnoDB | 500 |
| Large | RH Enterprise Linux | 4 cores/8GB | RAID 10 MySql ou PostgreSQL | >1000 |
| Very Large | RH Enterprise Linux | 8 cores/16GB | RAID 10 MySql ou PostgreSQL | >10000 |
4. Item básicos de Monitoração¶
Memória, CPU, Disco, Rede, Porta TCP e Serviços de Aplicações. Muitas da funcionnalidades avançadas do Zabbix estão relacionados ao agente que é instalado nos servidores da solução.
Por exemplo, o agente Zabbix possui as funcionalidades de ver as principais métricas do Oracle, PostgreSQL e MySQL
5. Item avançados de Monitoração¶
Uma das caracteristica do Zabbix é sua flexibilidade. Ele não se limita apenas aos itens dos seus agentes sem possivel fazer qualquer tipo de monitoração via shell scripts. A seguir alguns exemplos:
-
Web através da url e seus respectivos conteúdos e status
-
Scripts em bash
-
Validação de Backup
- Checagem de Validade do Certificado Digital
- Monitoramento dos Pods e Serviços do Openshift
- Qualquer saída do script bash
Onde utilizamos o Zabbix¶
- SMSUB – Integração com os sistemas de chamados SCCD e ITSM (Prodesp)
- SAA – Envio dos incidentes por email aos responsáveis
- SABESP – Envio dos incidentes por email aos responsáveis
- SOCICAM – Abertura de chamados automaticamente via sistema MILVUS
- PORTO DE SÃO SEBASTIÃO - Envio dos incidentes por email aos responsáveis
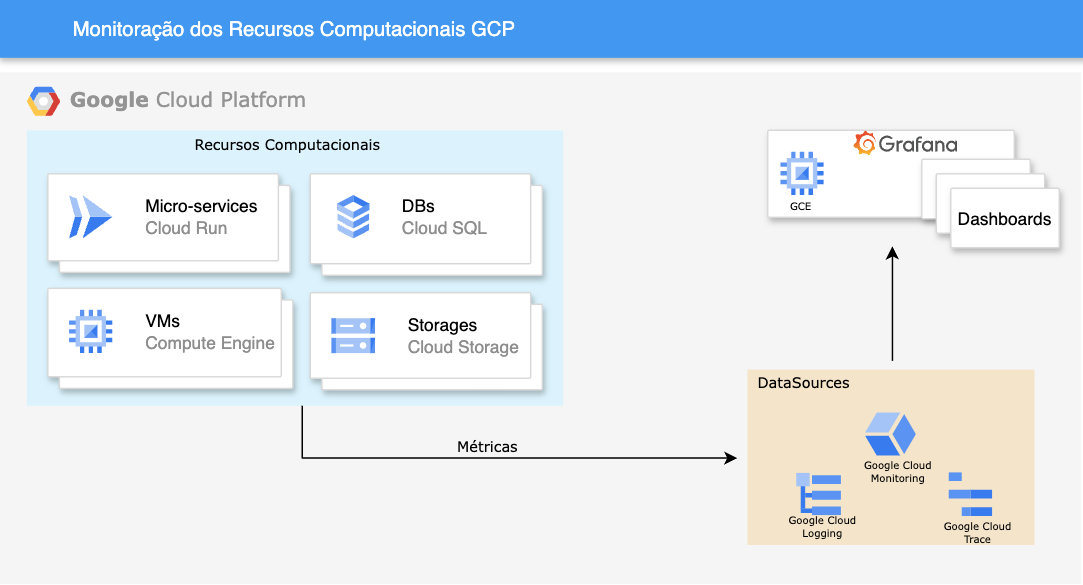
Monitoração dos recursos computacionais GCP¶
Visão Geral¶
Projetos que utilizam recursos computacionais GCP, podem ser monitorados pelo próprio Dashboard disponibilizado pelo provedor. Com isso, podemos realizar todas as atividades de observabilidade de um determinado ambiente, como:
- Análise de registros;
- Exploração de métricas e rastreamento;
- Alertas e consumo dos recursos.
Esta monitoração captura informações diretamente das APIs da GCP fornecendo métricas dos produtos gerenciados pela Google. Tem uma riqueza de detalhes importantes para os desenvolvedores uma vez que há correlação entre carga e consumo de recursos computacionais.
Podemos utilizar esses recursos pré-configurados ou criar nossos próprios Dashboards conforme as necessidades de cada projeto. Para isso, utilizamos um conjunto de ferramentas e recursos que juntos possam fornecer uma visão contínua do desempenho do sistema. Ao utilizar ferramentas como Grafana, Prometheus e dataSources específicos, é possível identificar proativamente problemas, otimizar recursos e estabelecer alertas para garantir a estabilidade e a eficiência da infraestrutura. Através da análise constante dessas métricas, a monitoração não apenas permite a detecção precoce de falhas, mas também oferece insights valiosos para aprimorar a utilização de recursos e manter a integridade operacional do ambiente.
Stack de monitoração¶
A equipe responsável por monitorar o ambiente, pode-se beneficiar de algumas ferramentas e datasources disponíveis para esse propósito e de forma gratuíta. Basicamente, podemos construir dashboards totalmente customizados e de acordo com as necessidades de cada projeto.
Para construir uma stack de monitoração, podemos utilizar os seguintes recursos:
- Google Compute Engine para a criação da instância.
- IAM para o controle de acesso aos recursos GCP;
- Grafana para a construção e apresentação dos Dashboards;
- Datasources para a coleta de métricas.
Utilizando uma instância GCE, instalamos a ferramenta Grafana para criar os dashboards e conectar certos recursos computacionis GCP, através de data sources específicos. Em seguida criamos uma conta de serviço com todas as Roles necessárias e associamos a mesma nessa instância. Assim, o Grafana terá permissão para coletar as métricas de cada Recurso GCP.
Todo esse processo de criação e configuração, poderá ser realizado de forma automática, utilizando outras ferramentas como Terraform para o provisionamento dessa instäncia e em seguida scripts shell para a instalação e configuração do Grafana.
O diagrama a seguir ilustra a solução desenvolvida:
Acesso ao Dashboard de Monitoração¶
Antes de se realizar o acesso ao Grafana, se faz necessário verificar os IP`s que foram associados a instância GCE. Essa máquina poderá ter tanto um IP interno quanto externo(não recomendado). Para acesso utilizando IP externo, informe o IP e porta 3000 em qualquer navegador web.
Para acesso ao Grafana utilizando um IP interno da instância, se faz necessário criar uma ponte do computador do usuário para uma outra instância GCE.
Em um terminal shell, execute o comando abaixo:
gcloud compute ssh --zone "southamerica-east1-b" "nome-da-vm" --project "seu-projeto" -- -L 1236:192.168.148.9:3000
Lembre-se de ajustar as informações, como a zona, o nome da VM e o projeto, conforme a configuração específica do seu ambiente.
Em seguida abra um navegador web e acesse o endereço http://localhost:1236 ⧉. Insira as credenciais adequadas, se necessário.
A partir desse ponto, o analista responsável já poderá criar seus próprios Dashboards, seguindo a documentação oficial ⧉ do Grafana.
Alertas do Google Cloud Platform¶
Alguns alertas poderão ser configurados diretamente na própria ferramenta Grafana ⧉ ou através do recurso Alert ⧉ do GCP. No grafana, basta editar o painel de uma determinada monitoração e verificar se existe uma aba de nome "Alert". Caso positivo, clique no botão New alert rule e siga as instruções apresentada na tela.
Para configurar esses alertas no próprio recurso GCP, será necessário criar uma política de alerta, selecionando a métrica que será monitorada, informar o treshold, selecionar um canal de notificação e definir o nome da política.